
Olá! Tudo bem? Este é o quarto e último artigo de uma série sobre inversão de controle. No primeiro artigo abordamos uma definição básica sobre o que é inversão de controle. Sob esta definição, apresentamos dois padrões de projeto que tornam possível esse princípio de desenvolvimento: Factory e Observer. Neste último artigo da série, vamos apresentar outras duas soluções que tornam possível a inversão de controle: Service Locator e Injeção de Dependência.
Antes de prosseguir, no entanto, preciso dizer que esses padrões fazem sentido se você estiver seguindo o princípio da Inversão de dependência. Aliás, vale dizer que Injeção de Dependência, Inversão de Controle e Inversão de Dependência são práticas comumente confundidas. É preciso frisar que são princípios, práticas e padrões diferentes, ainda que façam muito sentido se usados em conjunto. Estou escrevendo um artigo sobre DIP (Dependency Inversion Principle), onde pretendo aprofundar um pouco mais essa diferença.
Service Locator
Quando buscamos desenvolver softwares de qualidade, um dos princípios que precisam ser buscados com afinco é o do baixo acoplamento. Seja pensando em classes ou módulos, manter o acoplamento baixo (o que não quer dizer inexistente) é o que diferencia um código durável e rentável de outro código descartável e caro. Service Locator é um padrão de projeto que auxilia a equipe de desenvolvimento a seguir este princípio. Mas como?
O Service Locator encapsula a criação de serviços, devolvendo as instâncias requisitadas pelos clientes. Tendo em vista apenas esta descrição, ele pode ser facilmente confundido com uma “factory mais elaborada”. Mas não é verdade. O Service Locator saberá criar uma lista de serviços, não necessariamente diretamente correlacionados (no caso de uma aplicação monolítica, por exemplo), conforme estes são requisitados. Além disso, ele pode controlar o tempo de vida das instâncias solicitadas ao vinculá-las a um contexto – comportamento chamado de “Scoped”. Ou sempre retornar uma nova instância – comportamento chamado de “Transient”.
Como funciona o padrão Service Locator?
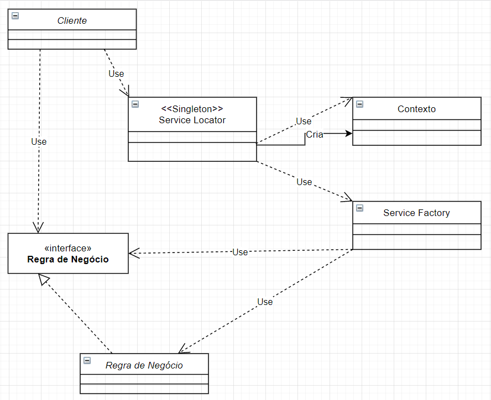
A classe Cliente requisita ao Service Locator a instância de um serviço. No diagrama chamamos o serviço de “Regra de Negócio”, dado que serviços devem representar regras de negócio, não é mesmo? Essa requisição pode ser feita através da apresentação de uma interface ou por meio de uma string (prefira não fazer isso) que defina o serviço.
Ao receber a solicitação, o Service Locator verifica o contexto (se ele não existir, será criado) para saber se a instância do serviço solicitado já existe. Se já existir, retorna a instância encontrada. Se não, solicita a criação do serviço ao Service Factory. Esta, por sua vez, contém a inteligência necessária para criar o serviço solicitado.
Você pode programar isso na mão, sempre adicionando novo código para cada serviço criado. Ou você pode utilizar recursos de meta-programação (Reflection, RTTI, ou qualquer outro nome que a sua linguagem dê para esses recursos).
public class Cliente
{
public void UmMetodoQualquer()
{
IRegraNegocio servico = ServiceLocator.Encontrar("RegraNegocio");
// ou
// IRegraNegocio serviço = ServiceLocator.Encontrar<IRegraNegocio>();
servico.Executar()
}
}
Como nada é perfeito, você consegue perceber qual é o problema dessa abordagem? Pense um pouco.
A instância do ServiceLocator precisa estar disponível para a classe que irá utilizá-lo. Para isso, você tem a opção de deixar alguma variável global visível para todo o sistema. Outra opção é injetar a instância do ServiceLocator em algum ponto da classe que irá utilizá-lo. Em ambos os casos será criada uma dependência ao ServiceLocator na classe que o utiliza. Mas não apenas na classe: a camada ou módulo em que essa classe está vinculada também se tornará dependente da implementação do ServiceLocator.
Uma arquitetura limpa não deveria depender de frameworks. Ou depender o mínimo possível. Modelos arquiteturais, como a Arquitetura Hexagonal por exemplo, afirmam que a camada de negócios deve ser completamente ignorante de framework, sistema operacional e demais detalhes técnicos. Ao adicionar a dependência do ServiceLocator em uma classe de negócio, perdemos a portabilidade e a reutilização de todo o módulo em outros sistemas.
Isso realmente não é nada bom. Por isso existe uma solução ainda melhor que Service Locator:
Dependency Injection
A verdade é que não podemos escapar das dependências e de certo nível de acoplamento. Do contrário, todo o código da sua aplicação estaria no bloco de inicialização. Como não podemos fugir dessa realidade, o que podemos fazer é criar dependências que façam sentido, enfraquecer essas dependências e automatizar, no código, tudo aquilo que é possível.
Então pense comigo: No exemplo acima, Cliente precisa saber quais são as dependências da RegraNegocio? Não. O quê Cliente realmente utiliza? O método executar da classe RegraNegocio. Cliente REALMENTE precisa do ServiceLocator? Não! Duvida? Se o código fosse escrito como abaixo, seria realmente necessário o ServiceLocator?
public class Cliente
{
readonly IRegraNegocio _servico;
public Cliente(IRegraNegocio servico)
{
_servico = servico;
}
public void UmMetodoQualquer()
{
_servico.Executar()
}
}Somente o fato de utilizarmos uma interface já deixava o nosso código com um bom nível de desacoplamento. Ao retiramos até mesmo o código referente a obtenção da instância desejada, o acoplamento ficou ainda mais enfraquecido. Não importa para a classe Cliente a origem da instância do serviço e tão pouco como ele é criado. Ela apenas comunica ao mundo: “Para me usar, vocês precisam dar para mim um objeto que implemente IRegraNegocio. Do contrário, nada feito”.
Parece que está tudo resolvido, mas não está! Já pensou o problema que isso pode causar? Se fizer essa injeção manualmente, você estará atrasando a criação dos objetos e apenas repassando essa responsabilidade para o topo da pilha de chamadas. Isso não é o ideal. No final, terá métodos com imensa lista de parâmetros e objetos sendo criados cedo demais. E é justamente aí que entra a Injeção de dependência. Ou melhor: container de injeção de dependência.
Ela é muito parecida com o Service Locator. A diferença é que, com base em todas as classes registradas, quando uma instância é requisitada ao Dependency Injection, ele automaticamente resolve todas as dependências. Se “A” tem dependência de “B” que tem dependência de “C”, que depende de ninguém para ser criado, o DI vai criar C, injetar em “B” e depois injetar em “A” e devolver “A” para o chamador. Muito esperto, não é?
Como utilizar Injeção de dependência?
Acredito que seja desnecessário explicar como funciona o padrão porque existem várias ferramentas de DI espalhadas pela web e cada uma funcionando de um jeito. Via de regra, o uso se dá conforme descrito no código acima: Você informa a dependência no construtor da classe e o injetor que estiver utilizando cria e injeta todas as dependências. Alguns outros injetores conseguem, por exemplo, injetar dependências em parâmetros de métodos, variáveis privadas e assim por diante.
As possibilidades variam de acordo com o que é permitido pela linguagem ou pela implementação. Os exemplos de injeção em variáveis privadas, por exemplo, eu encontrei apenas no CDI – que é o injetor default para Java. Injeção de dependência em chamadas de métodos também encontrei apenas em Java. Seria possível fazer o mesmo em Delphi ou em C#, mas demandaria algumas “piruetas”, envolvendo AOP ou até mesmo classes virtuais, o que na minha singela opinião não vale a pena.
E como eu comecei falando, este padrão faz muito sentido quando você está separando em camadas o desenvolvimento do seu software. O injetor de dependência seria parte da camada “crosscutting” do sistema, tornando possível a comunicação entre as diferentes camadas sem que elas exatamente conheçam umas às outras. Acoplando somente o necessário (o extraordinário é demais)!
Quando utilizar o Dependency Injection?
Se o teu sistema roda em cima de algum framework (ASP.NET, Spring e etc), é bem provável que ele já utilize algum container de Injeção de Dependência. E como ficaram bem mais fáceis de configurar, estão cada vez mais populares. O que pode levar a erros se usados de forma inescrupulosa.
Como já foi dito, quando estiver desenvolvendo em cima de frameworks, alguns já possuem o seu próprio injetor. Geralmente eles possuem notações e formas específicas de registrar as dependências. Para esses casos é quase que obrigação utilizar o DI ou nada funciona. Mas não se esqueça que DI não serve apenas para injetar Controllers. Outros detalhes técnicos também podem ser injetados via DI. Mecanismos de profile, log, configurações também podem ser acessados via DI.
O ponto de atenção, que é um erro comum para principiantes, é tentar injetar absolutamente tudo. Até mesmo DTO e Entidades. Isso não faz muito sentido, eu sei. E eu sei por que eu mesmo já tentei (blushed). Técnicas como TDD, por exemplo, ajudam a ressaltar esse tipo de erro de design de código. Você vai perceber que está errado porque ou ficou complexo demais ou você não consegue sair do lugar.
E por fim, o momento mais óbvio para utilizar um container de Injeção de Dependência é quando precisar integrar diferentes camadas. Segundo o Dependency Inversion Principle, não é permitido que camadas dependam de implementações, mas de abstrações somente. É exatamente o que foi descrito no exemplo do início do artigo. Como a dependência deve ser apenas entre as interfaces, fica a cargo do injetor saber qual classe instanciar e devolver o objeto correto ao chamador, trabalhando de forma transversal em todas as camadas.
Quando usar Service Locator?
Aqui entre nós, Dependency Injection, pensando no design da arquitetura do seu código, é mil vezes melhor. Ele diminui muito o acoplamento e é invisível para a maior parte do código. Quando então eu deveria utilizar o Service Locator?
Meu primeiro palpite seria em um cenário de transição. Você está em um monolito totalmente acoplado e quer ir fazendo as coisas devagar? Talvez você esteja em um legado em que não há nenhum framework que gerencie as requisições, controllers e etc e tal. Neste cenário faz muito sentido utilizar o Service Locator.
Agora, um cenário em que você pode se sentir tentando a usar Service Locator, mas não deveria: Uma classe qualquer utiliza mais de um serviço. Mas um deles somente será utilizado se um determinado método for invocado. Do contrário não seria necessário tê-lo criado. Neste cenário talvez você queira utilizar Service Locator. Afinal, o custo de criar um objeto e não o utilizar pode ser grande. São processamento e memória jogados fora. Para este caso, Service Locator seria uma solução preguiçosa. Não utilize.
A melhor solução para o cenário descrito acima seria você ter duas classes diferentes. Isso mesmo. Se as dependências variam conforme o uso, talvez a classe esteja se preocupando com mais de uma coisa. O que, em termos de design de projeto, é um erro. Ter dependências não utilizadas pode ser um sintoma de que é necessário aumentar a segregação das classes. Claro, se o projeto não permitir que a separação de conceitos seja feita, utilize o Service Locator. Mas pode acrescentar mais um ponto na sua dívida técnica.
Onde está a Inversão de Controle aqui?
Quando colocados em contraste com o Princípio da Inversão de Dependência (o DIP do SOLID), a Inversão de Controle fica quase que transparente em ambos. E eu concordo com você que o framework da aplicação ou até mesmo o DIP tornam o conceito mais claro. Mas sim, Dependency Injection e Service Locator também invertem o controle. Vou jogar luz neles pra você que não percebeu, possa notar.
Ambos os padrões possuem maneiras de controlar o ciclo de vida dos objetos gerados. Ou seja, não é o código da classe client quem controla o ciclo de vida dos objetos. Tão pouco é ela quem define quais instâncias deseja usar. No máximo ela conhece um nome de serviço ou uma interface. Todo o resto é controlado pelo container.
Não bastasse isso, o container de Injeção de Dependência ainda tem o plus de resolver as dependências. Ou seja, a classe não precisa sequer saber quem a está chamando (ainda que seja possível informar, dependendo do container). Ela apenas passará a existir. E em algum momento, deixará de existir. Como lágrimas na chuva. Totalmente isolada e sem controle de onde vai e para onde vem.
Conclusão
Caminhamos bastante, sem dúvida. E há muita coisa que, infelizmente, deixei passar. Tive que fazer cortes (bastante) ou essa série de artigos acabaria virando um livro! Então espero ter acertado nas minhas escolhas.
Também espero que você tenha aprendido um pouco mais sobre Inversão de Controle e como ela funciona na prática, junto de um pouco de teoria. Minha intenção era demonstrar o conceito de Inversão de Controle e, em conjunto, apresentar alguns padrões de projeto e outros princípios de desenvolvimento que a tornam possível. Geralmente estudamos esses mesmos padrões e princípios isoladamente. O que os deixam muito distantes da nossa realidade. E assim são esquecidos porque não fazem sentido. Espero que agora façam um pouco mais.
Deixo o espaço aberto para dúvidas, críticas e dicas de quais outros assuntos você gostaria que fossem abordados no blog.
Foi um prazer caminhar contigo até aqui. Nos vemos na próxima!
3 thoughts on “Inversão de controle Parte Final: Service Locator e Injeção de Dependência”