
Quando a gente está começando em uma linguagem, qualquer informação é logo absorvida como padrão. As vezes até sem nenhuma crítica. E isso óbvio, afinal, se você está dando os primeiros passos assume-se que não tem experiência o suficiente para criticar esta ou aquela abordagem. Uma dessas informações, em geral, é a forma como estruturamos o nosso projeto. Eu quero apresentar como estruturar o seu projeto C# de uma forma bastante inteligente, visando a praticidade do desenvolvimento. E fique à vontade para adicionar os seus comentários.
Mas antes, um ponto polêmico:
Um ou vários projetos na solution?
Acredito que o padrão mais famoso é a criação das pastas [API | Console | Worker], Domain, IoC e Infra, cada uma representando um projeto. Eu tenho certeza absoluta de que se você já programa profissionalmente em C#, já viu alguém utilizar esse “template” em algum projeto. Pode ser apenas um “hello world” que esses projetos estarão lá. Faz sentido isso? Eu digo que depende.
Essa estrutura me remete à Arquitetura Hexagonal e do meu ponto de vista, ela é muito bem aplicável para casos em que realmente há complexidade de domínio. Em casos como esse, quanto mais organizado o projeto e mais separadas as responsabilidades, melhor. Outra vantagem intrínseca desta abordagem é a ajuda do compilador. Ele irá pintar o terminal de vermelho caso você viole a hierarquia de camadas, ou caia no buraco negro da referência circular.
Contudo, manter todas as camadas perfeitamente isoladas tem um preço: aumento exponencial de complexidade. E talvez você não queira isso em um projeto que, por natureza, deveria ser simples. Seus olhos vão doer, mas em determinados casos é perfeitamente aceitável ter o DbContext no Controller. Uma simplicidade que pode te dar os milissegundos que você precisa e principalmente: eliminar a complexidade desnecessária.
Tem um caminho do meio?
Eu acredito que sim. Se olharmos friamente, a alternativa a trabalhar com um projeto só seria ter o código organizado em pastas, o que nos faria voltar, de certa forma, ao template que iniciou essa discussão. Com a organização em pastas não contaríamos com o auxílio do compilador, é verdade, mas temos ferramentas como o NDepend que podem fazer essa análise para nós.
Para aquelas pessoas que não desejam abrir mão dos múltiplos projetos na solution, minha recomendação então é a de que esqueça a palavra domínio. Esta palavra carrega uma carga conceitual muito pesada. Se você acha ofensivo ter o DbContext no Controller, imagine ter os objetos de Response/Request no Domínio? Ou ainda, ter um Domínio que sabe detalhes da obtenção/persistência de dados, conhece os protocolos de comunicação… Nesse “caminho do meio” o conceito de domínio deve ser totalmente afastado.
Desculpe se o tom pareceu meio “ditatorial”. Está tudo bem você discordar de mim. Em um artigo de opinião não existe certo e errado. O que existe é: “será que essa opinião faz sentido pro meu caso?”. Encontrar um nome para substituir “domain” é uma tarefa que você deve executar junto com o time. E tem de fazer sentido para todos. Inclusive vocês podem chegar à conclusão de que “domain” é a melhor nomenclatura. Tudo bem. Desde que toda decisão faça sentido e possa ter o que “porquê” respondido, tá ótimo!
Vamos para mais polêmicas!
Utilizar pastas de projeto
Você já sabe, mas não custa lembrar: Pasta de projeto são “pastas virtuais” criadas no arquivo sln. Em disco você tem uma estrutura que não é exatamente refletida no Solution Explorer do Visual Studio. Em geral, as pessoas fazem uso desse artifício para “organizar melhor o código”, fazendo com que algumas pastas apareçam primeiro ou fiquem dentro de subpastas. A pergunta que eu faço é: Por que não refletir essa organização em disco também?
Se você trabalha com alguma IDE ou editor de texto que não faça o parsing dessas informações, a única visão que você terá é a do que está em disco. Como o uso de IDE’s e editores de texto é uma escolha particular, manter o código em disco organizado, também é uma abordagem inclusiva. Nesse sentido, acredito que a estrutura dos projetos em javascript tem muito a nos ensinar. E se você já programou em NodeJs, vai perceber uma proximidade diante da estrutura que vou compartilhar com vocês agora.
A estrutura que eu acho ideal
O repositório de código hoje não possui apenas o código de produção. Também temos código de infra, código de pipeline, código de configuração do repositório, código de validação do código… Ufa! E olha que eu ainda não terminei a lista. Toda essa informação não pode ficar jogada dentro das pastas do repo. Precisamos de uma maneira organizada de manter esses arquivos. E essa é a minha proposta – que na verdade não é minha, mas totalmente inspirada nos projetos nodejs que participei.
Estruturando código de produção e de testes
Até o momento tenho trabalho apenas com testes de unidade e testes e2e nas minhas aplicações. Apesar dos testes também serem códigos, eu prefiro separá-los em estruturas distintas do meu código de produção – que é como chamo source que será “deploiado”. Desta forma, na raiz do projeto tenho duas pastas: ./__tests__ e ./src.
Além da qualidade de entrega, testes também servem de documentação. Por isso procuro refletir nos testes a mesma estrutura que tenho no código de produção. Assim eu consigo que os testes rodem com velocidade (já que ele testa a solução apenas quando necessário) e posso deixá-los rodando enquanto executo um dotnet watch -p ./src/MeuProjeto.Infra.Tests ou algo do gênero.
Tanto no código de produção quanto no código de testes, também gosto de manter minhas classes no menor escopo possível. Assim, em ./MeuProjeto.Infra.Tests/Brokers provavelmente você vai encontrar uma pasta Fixtures com todas as classes de apoio aos testes. Já em se tratando de código de produção, acho válido que cada projeto/módulo saiba resolver as suas dependências internas. Assim, você pode ver vários diretórios ./Extensions com as classes de extensões – tanto as ServiceExtensions (com código de extensão para IServiceCollection) quanto as EnumExtensions, por exemplo.
Estrutura para o código de infraestrutura
Não estou falando da camada de infraestrutura da sua solução. O caso é que, além do código propriamente dito, hoje temos infraestrutura como código, temos configuração de imagens, containers, kubernetes, pipelines e mais um número sem fim de requisitos necessários para a nossa aplicação entrar no ar.
Para este tipo de código, reservo pastas específicas dentro do repositório. Algumas são obrigatórias a depender do repositório e/ou produto que esteja utilizando. O GitHub, por exemplo, precisa que os arquivos de configuração do repositório fiquem dentro da pasta./.github. Se você usa Circle CI, também deverá ter uma pasta ./.circleci. Até mesmo as IDE’s utilizam a pasta raiz para armazenar suas pastas de arquivos temporários (./.vscode e ./.vs são bons exemplos).
Já a conteinerização do projeto nos dá um maior controle sobre essa estrutura quando o pipeline é escrito por nós. Ainda assim, gosto de não fugir muito do padrão. Crio pastas na raiz do projeto para cada uma das configurações. Logo, você vai ver uma pasta ./.docker, onde armazeno as minhas imagens; uma pasta ./.kubernetes, onde ficam os arquivos de template do kubernetes e assim por diante.
Outros arquivos
Se você acha que acabou, achou errado! Tenho certeza de que você ainda utiliza alguns arquivos que te ajudam em tarefas cotidianas. Por exemplo: checar a cobertura de código, automatizar a escrita de dockerfiles, configurações de code style entre tantos outros arquivos e scripts que auxiliam no dia a dia da codificação.
Esses arquivos são os poucos (as vezes não tão poucos) que eu deixo “largados” na pasta raiz. Não preciso deles categorizados, deixá-los na raiz do projeto pode deixar o meu trabalho mais fácil – e em algum momento, pode ser obrigatório por alguma feature que você esteja usando. Se você estiver usando o Husky, por exemplo, o arquivo de configuração dele pode ficar na raiz do projeto. O .gitignore, com certeza, precisa ficar na raiz. O seu .editorconfig, .ruleset, stylecop.json e assim por diante.
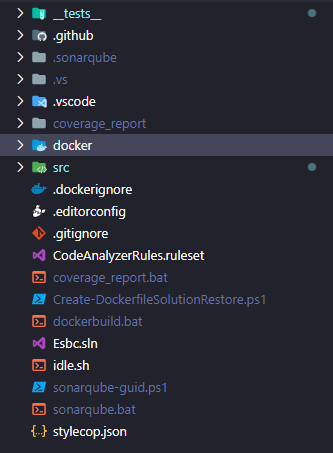
Na imagem acima, você vê como eu gosto de organizar meus projetos pessoais. Algumas pastas são geradas automaticamente pelos meus scripts (como a pasta .sonarqube, por exemplo). Antes eu usava scripts para checar a qualidade do código. Já não preciso mais disso porque configurei GitHub Actions que validam o meu código no sonar. Também tenho script que gera a linha que copia os *.csproj no dockerfile. Diversas “mãos na roda”.
Como eu disse, é um artigo de opinião. Não tem certo ou errado. Eu simplesmente prefiro uma organização que diminua a minha carga cognitiva ao máximo e que me permita, no final das contas, ter menos trabalho e ser mais produtivo no que realmente interessa: a entrega. Cada milissegundo conta!
E você? Como você organiza seu código? Deixe sua dica nos comentários. Vou gostar muito da sua opinião!
Um abraço e até a próxima
Concordo plenamente, cada milissegundo conta!!!!!